מאת תומר אולמן ואלון יקטר
הכותבים הם מרצים וחוקרים באוניברסיטת הרווארד, המחלקה לפסיכולוגיה (אולמן), ובבית הספר למדע המדינה, ממשל ויחסים בינלאומיים באוניברסיטת תל אביב (יקטר). המאמר עובד משרשור של אולמן בטוויטר ומתפרסם בהסכמתם.
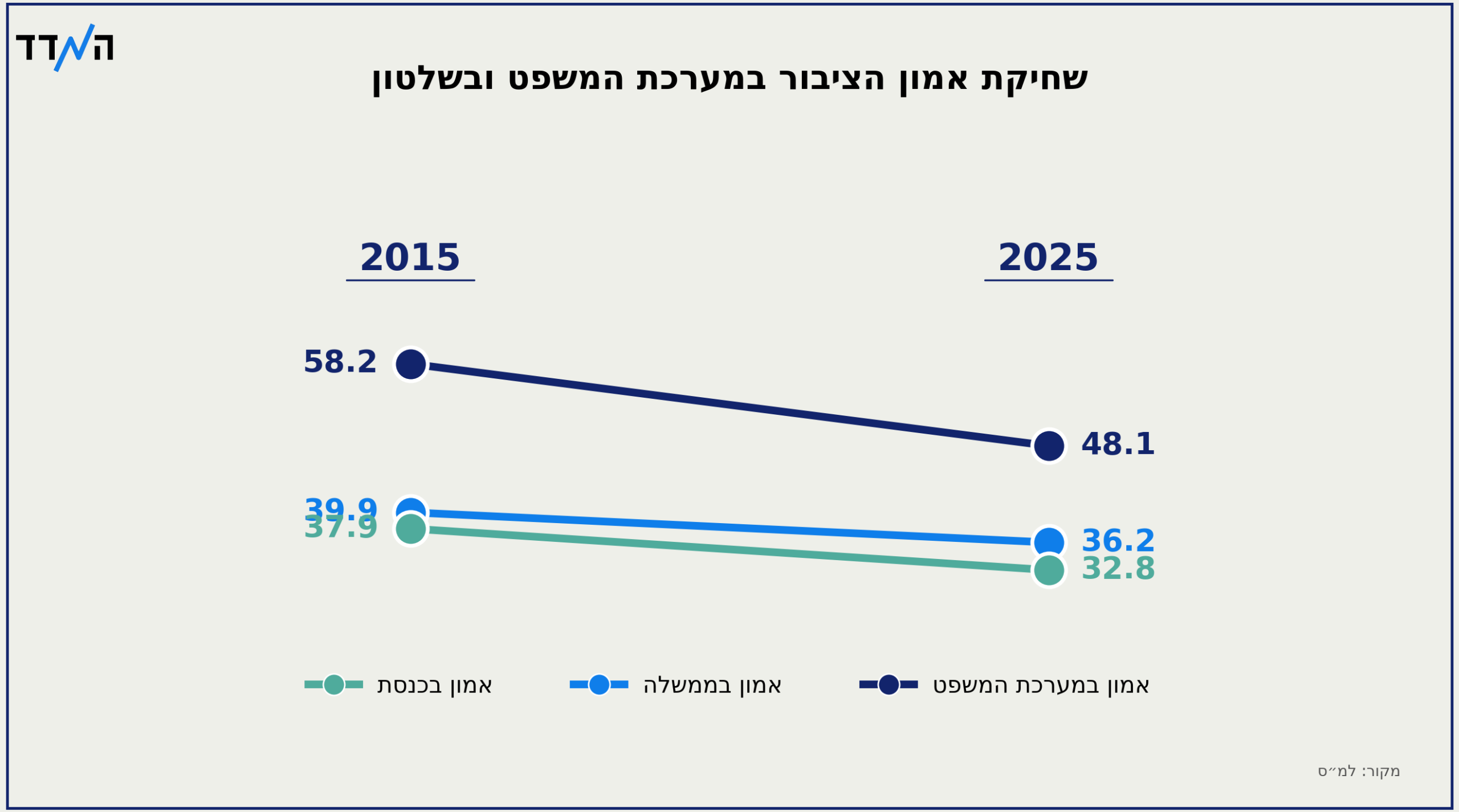
החדשות בישראל מוצפות בסקרים לקראת הבחירות. הסקרים קפואים ודומים אחד לשני. על פניו, סימן שהם אמינים, והמציאות פשוט קפואה. אבל האם הסקרים קפואים ומסכימים ״מדי?״ בדקנו ונראה שהתשובה היא: כן, הם דומים מדי.
הנה הסבר:
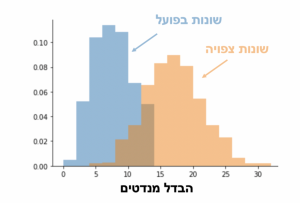
לכולנו ברור שאם סוקרים 800 איש באקראי, ואז 800 איש אחרים, יכול להיות הבדל בין שני הסקריo/ ההבדל הזה ׳צפוי׳, והוא ׳אמור׳ להיות בגודל מסוים.
הבדלים גדולים מדי בין סקרים מעידים על בעיה. אבל גם הבדלים ׳קטנים מדי׳ מעידים שמשהו לא תקין. לא הגיוני שכל הסקרים ינפקו תשובות כמעט-זהות. בסקרי הבחירות בישראל, ההבדל בפועל בין הסקרים קטן פי 2.5 ממה שהוא אמור להיות.
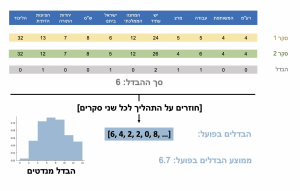
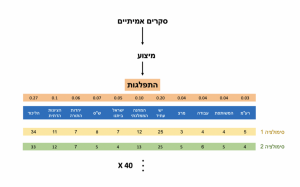
איך בודקים את ההבדל בפועל? ניקח את ~40 הסקרים האחרונים (ותודה למאגר של המדד) נסתכל על סך הבדל המנדטים בין 2 סקרים. נחזור על זה לכל זוג סקרים, ונקבל התפלגות הבדל בפועל. הבדל המנדטים בין הסקרים ׳בפועל׳ הוא 6.7. זה הרבה? מעט? בדיוק נכון? איך יודעים מה ההבדל ׳הצפוי?׳
נעשה סימולציות, ׳כאילו׳ עשינו את הסקרים האמיתיים שוב ושוב באופן נקי ובלי הטיות.
1.
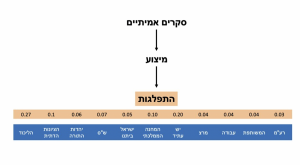
נמצע כמה 11 המפלגות הגדולות קיבלו ב-40 הסקרים האחרונים. זה ייתן לנו התפלגות, מין ׳אוכלוסייה׳ שממנה נדגום סקרים-בכאילו (לא רלוונטי אם ההתפלגות מתאימה למציאות, אנחנו בודקים את הסקרים כנגד עצמם).
2.
עבור כל סקר אמיתי, נדגום ׳סקר-כאילו׳ מההתפלגות על ידי דגימה אקראית של אנשים מדומיינים בכמות זהה לסקר המקורי. אם הסקר המקורי כלל 800 איש, נסמלץ 800 איש. נחלק ב-120 ונקבל תמונת מנדטים.
3.
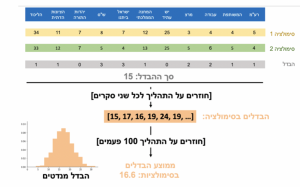
נחזור על (2) 40 פעמים.
4.
עבור 40 הסקרים המדומיינים, נעשה את אותו דבר שעשינו עם הסקרים האמיתיים (הבדלים בין כל זוג סקרים, סך ההבדל, וכו׳).
5.
נעשה את (4) 100 פעמים. זה נותן לנו את ההבדל ה׳צפוי׳, והוא: 16.6. כלומר, ׳פי 2.5׳ מההבדל שאנחנו רואים בפועל. הסקרים לא סתם קפואים, הם קפואים מדי.
למה הסקרים קפואים ודומים מדי? כנראה בגלל התערבות הסוקרים. יש לרובנו הנחה נאיבית שסקר שואל מדגם מייצג דמוגרפית של (נגיד) 800 איש ומדווח מה שיצא. אבל זה לא מה שסוקרים עושים. סוקרים עושים תיקונים כבדים לדגימה, לפי הנחות על מגזר, גיאוגרפיה וכו׳. ולרוב הסוקרים יש אותן הנחות.
לדוגמה, אם המדגם שלי כסוקר כולל ״יותר מדי״ צעירים יחסית לאוכלוסייה, אני צריך לנחש איך האוכלוסייה המבוגרת תצביע, לפי המעט שיש לי. אם הניחוש שלי ושל סוקר אחר דומים, ההתאמות שלנו יהיו דומות. הבעיה מחריפה אם הסוקרים מניחים הנחות דומות על אותן קבוצות קשות לדגימה (ערבים, חרדים וכו׳).
סוקרים רבים גם לא תמיד זורקים את האנשים שאומרים ״לא יודע״, אלא מניחים שהם מתחלקים באופן דומה לאלה שכן ענו, או שיצביעו כמו בבחירות הקודמות. כל כלל שמחלק את קבוצת המתלבטים באופן דומה בין הסקרים במקום לזרוק אותם תורם להקטנת ההבדלים באופן מלאכותי.
יתכנו עוד סיבות, אבל הנקודה העיקרית היא זו מהפתיח: השונות בין הסקרים קטנה מדי ביחס לצפוי, גם בעולם שבו איש כבר לא משנה את דעתו. התוצאה מעידה על ערבוב של נתונים חלקיים עם ניחושים מושכלים שמשותפים לסוקרים שונים. הקיפאון שהם מציגים דומה לקרחון: מעט גלוי, והרבה מתחת לפני השטח.